
Setting up Staticman for comments on a Jekyll blog
# 21 Dec 2017 by Sean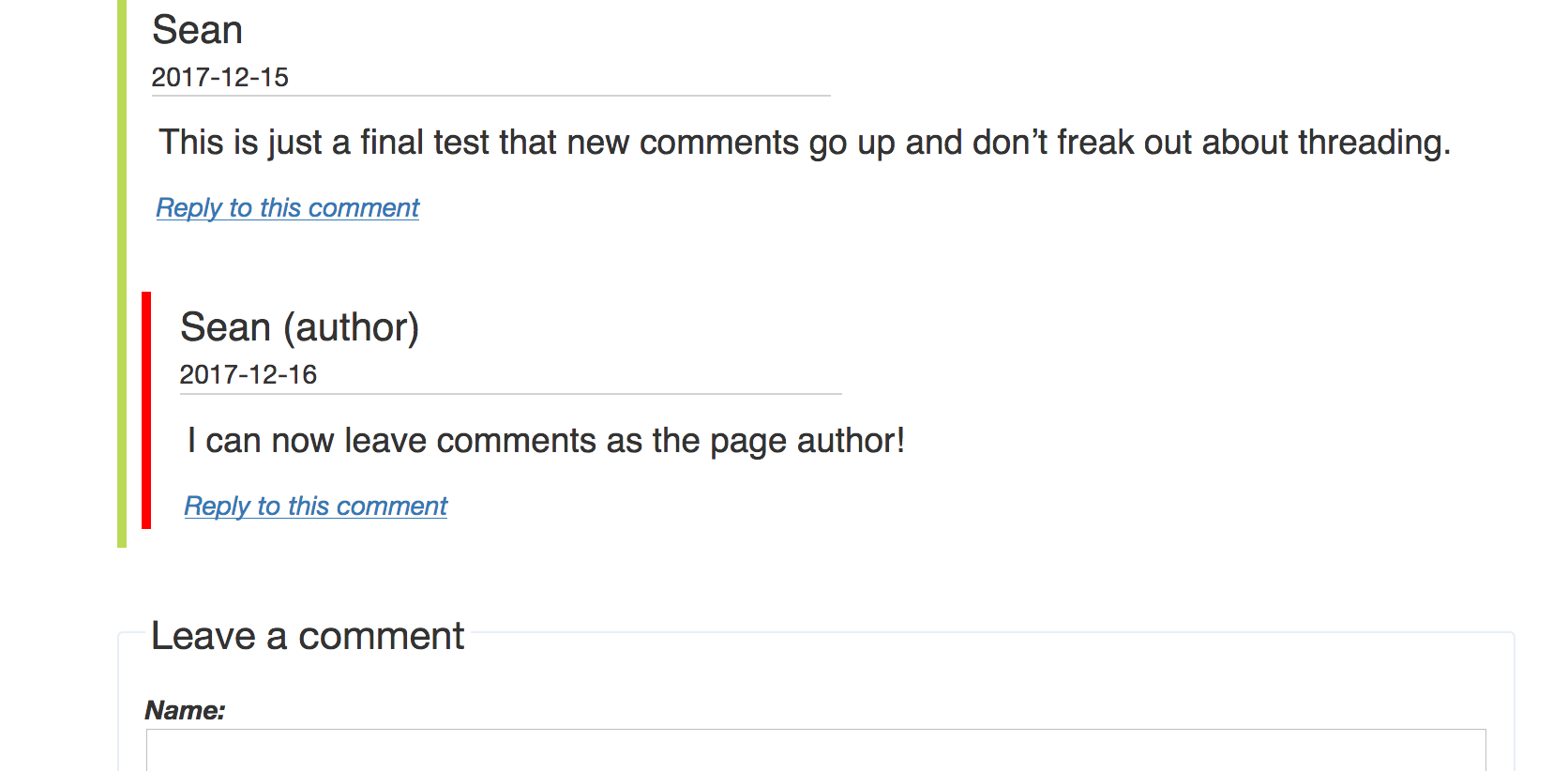
Despite the fact that I’m not really a front-end dev, getting threading to look decent was not the hardest part of this.
I’ve been wanting to set up Staticman on this site for a while. I took a swing at it a year or so ago, but either because I was less experienced with working with webapps and I was insisting on running up my own instance, or because it’s in Node and I’m a Ruby dev primarily, or because ¯\_(ツ)_/¯, I couldn’t get it to work. I ended up adding Disqus to the site, but since they just got bought and I have no idea who the new owners are, I’ve finally gotten around to setting up Staticman. There is an excellent post on Made Mistakes about this that I’ve cribbed a lot from, but there were a couple of gotchas I ran into that took me a while to solve.
What is Staticman
Staticman is a Node application that makes it possible to set up commenting for static sites and blogs, which would otherwise be impossible due to their static nature (ain’t no PHP here!). It accepts POST requests from a form you include somewhere on your site, and then makes PRs to your site’s Github repo with the comment’s content.
On a Jekyll site, the common approach to this would be to have Staticman create a new JSON or YAML file per comment in the site’s _data/ directory, then have an include in each post check site.data.comments for any comments on the post, and render them out at build time.
This means that once the comment is made, the next time the site is built1, the comment is visible at the bottom of the post, but the page will load as fast as it did without comments, since there’s no code running against a database to push them out to the user. Kinda cool.
Implementation
My setup isn’t too different from what I just described in the previous section. Let’s go step by step…
- I added
staticman.ymlto my site repo’s root. This contains some basic config options for Staticman, like which fields to allow data in. It must contain the production branch (or testing branch for development, but don’t forget to change that) for your repository’s website - Add the
staticmanappapp as a collaborator to your Github repo (this is why I’ll eventually be running my own instance) - Once added, you need to hit the API in your browser, providing your GH username, the branch, and a little bit more (the docs will walk you through it) to authorize the set up
With all the setup done, here’s what happens on this site:
- An include,
post_comments.html, adds a form to the bottom of each post where comments are enabled. The form submits a POST request to the Staticman API. The form’s<input>elements all have names likename=fields[commenter_name]orname=[commenter_email], because Staticman will reconstruct these into a Hash to generate the JSON it sends to your repository. The names you put into the brackets can be whatever you want, as long as they match between yourstaticman.ymlconfig file, the form, and the partials that render the comments - The Staticman app, on receiving the POST request from the form, creates a new branch and PR against my production repository (you can customize the commit message and PR title), which includes all the data submitted by the form in JSON (default is YAML). Github sends me an email, and I review the PR and comment. Here, these JSON are created as
_data/comments/[post-date]-[post-slug]/[comment-id].json, which makes them all available as part ofsite.data.comments - If it looks kosher, I merge the PR, which triggers a new build in my CI. The same
post_comments.htmlinclude will check ifsite.data.comments[page_filename]2 exists, and if so, will read each comment out and insert it into the page. - Once the site is built, my CI spits it at S3 and invalidates the Cloudfront cache, and the comment is live on the site, no backend code needed.
This is a pretty fast run through the setup, and I would totes encourage you to check the Staticman docs, or the Made Mistakes post (which is ace) for more detail.
Threading comments
You can see in the screenshot I’ve added to this post that the comments are threaded. It’s not too hard to make work. The Made Mistakes post sets up threading using an index based on the number of iterations gone through by the comment partials (there’s a healthy bit of recursion involved), but that felt off to me–I want this content and data to be portable, and I have no guarantee that whatever SSG or CMS I use in the future3 will iterate in the same way. Jekyll, for one, indexes its loops from 1, not 0, which could already throw me off in other situations.
Instead, I’m threading based on the comment ID, which is an attribute generated by Staticman. Once each comment is rendered by Jekyll, the comment partial makes another call to site.data.comments, this time specifying that it only wants comments that are replies to the current comment:
# preassign this because you can't index into the hash in Jekyll where expressions without nightmares
# also, bear in mind that include.id is the ID for the current comment as passed to the include
{% assign comment_id = include.id %}
{% assign replies = site.data.comments[file_name] | where_exp:'reply', 'reply.replying_to == comment_id' | sort: 'date' %}
This returns an array of the comments on the post that are in reply to the current comment. You then just loop over them and render them (and check for further replies) the same way you did the first time. Worth pointig out, the top parent comment loop also has a where_exp actually, that specifies only comments where replying_to is blank.
Here’s the full parent/top-level comment loop:
{% assign comments = site.data.comments[page_filename] | where_exp:'item', "item.replying_to == ''" | sort: 'date' %}
{% for comment in comments %}
{% assign index = forloop.index %}
{% assign id = comment['_id'] %}
{% assign url = comment['url'] %}
{% assign name = comment['name'] %}
{% assign date = comment['date'] %}
{% assign message = comment['message'] %}
{% assign author_id_secret = comment['author_id_secret'] %}
{% include comment.html index=index
id=id
url=url
name=name
author_id_secret=author_id_secret
date=date
message=message
%}
{% endfor %}
# Render commenting form here.
And the full reply loop:
{% capture i %}{{ index | strip }}{% endcapture %}
{% assign replying_to_id = include.id %}
{% assign replies = site.data.comments[page_filename] | where_exp:'item', 'item.replying_to == replying_to_id' | sort: 'date' %}
{% for reply in replies %}
{% assign index = forloop.index | prepend: '-' | prepend: include.index %}
{% assign id = reply['_id'] %}
{% assign r = reply.replying_to %}
{% assign replying_to = r | to_integer %}
{% assign email = reply.email %}
{% assign name = reply.name %}
{% assign author_id_secret = reply.author_id_secret %}
{% assign url = reply.url %}
{% assign date = reply.date %}
{% assign message = reply.message %}
{% include comment.html
index=index
replying_to=replying_to
id=id
email=email
name=name
author_id_secret=author_id_secret
url=url
date=date
message=message
is_reply=true
%}
{% endfor %}
(that little bit about capturing and passing the loop index are what Made Mistakes uses to link replies to parents, but I’m actually using them a little bit to style the replies–if you chain then, it’s kinda handy).
Including reply_to ID’s in the form
I’m proud of this. Replying to a comment is only possible with JavaScript (unless I rendered a form on every comment, which I really don’t want to do).
The form has a hidden field that accepts the ID of the comment being replied to, and each comment has a <data> element whose value is the post’s ID. On page load there’s a bit of JavaScript that appends a button to each comment, after the <data> element, and gives the button an event listener.
When the listener triggers, it takes the ID from the <data> element, inserts it into the hidden ID field in the form, then, helpfully, scrolls the user down to the form.
I’m debating making comment IDs and the form field visible so people can reply to comments without JS, but the IDs are fugly, and I don’t actually think anyone would do it…
You also need to include the replying_to field in both the list of permitted fields in staticman.yml, and in the list of required fields. This ensures you don’t end up with comments that are never visible because the field is entirely missing.
Jekyll and the nightmares of passing data
So… Liquid is not a great language. It does a lot of really cool things, but the number of times I found myself wishing I was using ERB…
I ran into a big problem when I was first setting this up. I don’t know about you, but the argument lists on those comment includes are terrifying. My first approach didn’t have them. Instead it just passed in the comment comment=comment, and then indexed into it inside the next include like comment['name'].
Problem was, when I went to get the comment ID out to set up threading, Jekyll freaked the eff out and threw errors about Nesting too deep. It was not pretty. So… argument lists.
I’m still not sure why this happened–the traceback is less than stellar. My problem is that I keep treating Jekyll like it’s Ruby, and it’s not. It’s close in its general friendliness, but it is not a robust programming language. I spent a lot of time calling {{ comment_id | inspect }} trying to figure out exactly where the error was.
If you run into the error, I’d recommend checking how much and what kind of data you’re passing and how often. Stack Overflow does also suggest it can be caused by custom Jekyll plugins (which I have), but disabling them didn’t fix it for me in this case. I think the Made Mistakes approach ran into it as well, but for slightly different reasons.
Identifying myself as the author
If you were looking closely at the liquid codeblocks earlier, you’ll have seen that I’m passing the includes a author_id_secret attribute. This is actually a hash of a secret key I’ve got.
When the comment partial is rendering the name, it checks to see if the include has that value, and if it matches what the site knows is the right hash. If it finds a match, it adds “(author)” after my name in the comment header. (The Made Mistakes approach just checks for a match between the comment author name and the page author name, which felt a little too easy to abuse to me).
There’s a field on the form that accepts the token to submit to Staticman, and I’ve got a Greasemonkey script that inserts it to any pages on my website if it can, which means I can always reply and be IDed as the author.
-
In my case, the minute I approve the PR because Codeship watches the production branch and will spit the generated site at AWS S3. ↩
-
I’ve set up a custom Jekyll plugin that adds a
.filenameattribute to each page object, pretty much just for situations like this. The default Jekyll and Staticman behavior is to put each post insite.data[page.slug], but without the slug preceded by the date it’s possible you’d have namespace clash in the_datadirectory.page.filenameis being pre-assigned topage_filenamebefore checking because Jekyll can get a little fussy when passing variables… more on that soon. ↩ -
So… Jekyll is really slow, and it just gets slower the more conditional logic you set up in the templates, which is what threaded commenting is all about. My current build time is about 4 seconds. Not bad for production, but kind of a pain in development and drafting. Much as I love Jekyll and the fact that I can easily hack it because it’s Ruby, I’m probably going to be moving to Hugo soonish. ↩